kafka消息格式有两种,一种是V1一种是V2
V2是由Kafka 0.11.0.0版本后引入的消息格式
不论是哪个版本,Kafka 的消息层次都分为两层:消息集合(message set)以及消息(message)。一个消息集合中包含若干条日志项(record item),而日志项才是真正封装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
V2相对于V1进行了很多改进,比如CRC校验的优化,以及对空间的优化,对比于V1的未压缩的空间占用,大概能有百分之10左右的空间节省。
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。
EX:在properties中指定压缩算法
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启GZIP压缩
props.put("compression.type", "gzip");
Producer producer = new KafkaProducer<>(props); producer 端和broker端 压缩算法应该指定相同,否则可能导致重新压缩消息的问题。
通常表现为 Broker 端 CPU 使用率飙升。
还有可能在消息格式不同的情况下,V2向下兼容会导致 重新 / 解压缩,也会让kafka丧失了引以为傲的0拷贝特性。
各种压缩算法 benchmark:
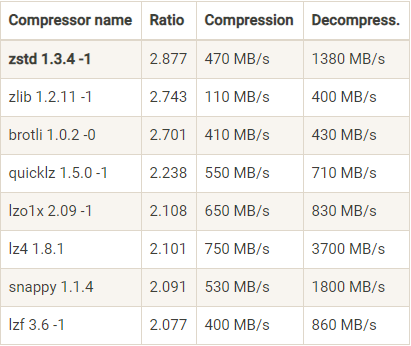
压缩消息还能显著降低网络带宽压力。
总结:
该节主要讨论了 Kafka 压缩的各个方面,包括 Kafka 是如何对消息进行压缩的、何时进行压缩及解压缩,还对比了目前 Kafka 支持的几个压缩算法,希望你能根据自身的实际情况恰当地选择合适的 Kafka 压缩算法,以求实现最大的资源利用率。