本文章简要概述了spark sql 的执行流程以及基本原理。
spark sql 本质是将sql 语句解析为对应的RDD模型来进行执行spark 相关的计算操作。
在spark 中,RDD中的窄依赖是类似于pipeline 来进行执行操作的,宽依赖是需要在不同的节点进行shuffle操作。
总的来说,RDD 能很方便的支持MapReduce应用、关系型数据处理、流式数据处理、以及迭代型的应用。
在spark 2.0中Dataset 成为了spark中主要的API,结合了RDD以及DataFrame的特点,属于spark的高级API。
spark sql 简要执行流程过程概览:
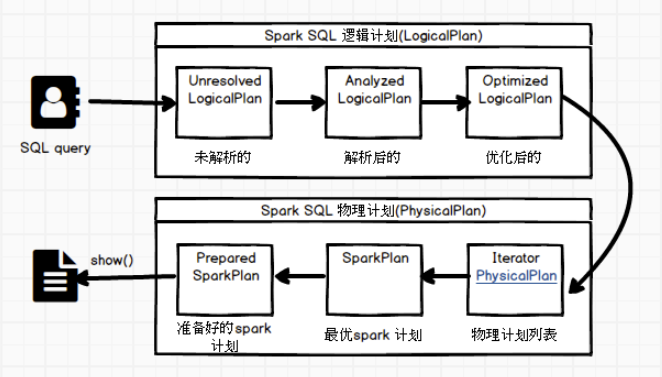
LogicalPlan 阶段会将用户所输入的SQL Query transition to 逻辑算子树,sql 语句中所包含的逻辑映射到逻辑算子树的不同节点,且逻辑算子树不会进行执行,只会作为中间阶段。
逻辑算子树三大子阶段:
(1)Unresolved LogicalPlan(未解析逻辑算子树),仅仅只是数据结构,其中不包含任何数据信息。
(2)Analyzed LogicalPlan(解析后的逻辑算子树),节点中绑定各种信息。
(3)Optimized LogcalPlan (解析优化后的逻辑算子树),应用各种优化规则对一些低效的逻辑计划进行转换。
物理计划阶段,会将上一步逻辑计算阶段生成的逻辑算子树来进行实际转换,生成物理算子树,其中物理计划阶段会直接生成RDD 或者对RDD来进行transformation 操作,来对应sql ,到最后才进行action操作(如实例中的show操作),来对RDD来进行实际提交执行。
其中SQL 语句在解析一直到提交之前,上述的整个转换过程都是在spark集群中driver端来进行的,不涉及分布式环境,sparkSession 类的sql 方法调用sessionState中的各种对象,包括上述的不同阶段生成的对应的SparkSqlParser类、Analyzer类、Optimizer类和sparkPlanner类等,最后封装成一个QueryExcution对象。因此,在进行sparkSql开发的过程中,可以很方便的将每一步生成的计划单独的剥离出来进行分析。
重点:
spark SQL 内部实现上述流程中平台无关部分的基础框架称之为Catalyst。
Catalyst中主要包括了InternalRow体系、TreeNode体系、和Expression体系。