1.1 分布式计算框架
1.1.1 编程模型
1. inputformat
在MapReduce程序的开发过程中,往往需要用到FileInputFormat与TextInputFormat,我们会发现TextInputFormat这个类继承自FileInputFormat,FileInputFormat这个类继承自InputFormat,InputFormat这个类会将文件file按照逻辑进行划分,划分成的每一个split切片将会被分配给一个Mapper任务,文件先被切分成split块,而后每一个split切片对应一个Mapper任务
FileInputFormat的划分机制:
A. 简单地按照文件的内容长度进行切片
B. 切片大小,默认等于 block 大小
C. 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
默认情况下, split size =block size,在 hadoop 2.x 中为 128M。
注意:bytesRemaining/splitSize > 1.1 不满足的话,那么最后所有剩余的会作为一个切片。从而不会形成例如 129M 文件规划成两个切片的局面。
2. MaTask端的工作机制
input File 通过 split 被逻辑切分为多个 split 文件,通过 Record 按行读取内容给 map(用户自己实现的)进行处理,数据被 map 处理结束之后交给 OutputCollector 收集器,对其结果 key 进行分区(默认使用 hash 分区),然后写入 buffer,每个 map task 都有一个内存缓冲区,存储着 map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个 map task 结束后再对磁盘中这个 map task 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task 来拉数据。 Map端的输入的(k,v)分别是该行的起始偏移量,以及每一行的数据内容,map端的输出(k,v)可以根据需求进行自定义,但是如果输出的是javabean对象,需要对javabean继承writable
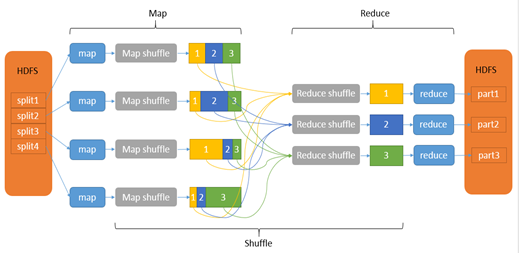
3. shuffle的过程
shuffle的过程是:Map产生输出开始到Reduc取得数据作为输入之前的过程称作shuffle.
1).Collect 阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value,Partition 分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数据进行排序。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个
MapTask 最终只产生一个中间数据文件。
4).Copy 阶段: ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge 阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线
程对内存到本地的数据文件进行合并操作。
6).Sort 阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask阶段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认 100M
2. reduceTask
reducer将已经分好组的数据作为输入,并依次为每个键对应分组执行reduce函数。reduce函数的输入是键以及包含与该键对应的所有值的迭代器。
reduce端的输入是map端的输出,它的输出的(k,v)根据需求进行自定义
reducetask 并行度同样影响整个 job 的执行并发度和执行效率,与 maptask
的并发数由切片数决定不同,Reducetask 数量的决定是可以直接手动设置:
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在 reduce 阶段产生数据倾斜。
默认的reduceTask的是1
*Task并行度经验之谈:
最好每个 task 的执行时间至少一分钟。如果 job 的每个 map 或者 reduce task 的运行时间都只有 30-40 秒钟,那么就减少该 job 的 map 或者 reduce 数,每一个 task(map|reduce)的 setup 和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task 都非常快就跑完了,就会在 task 的开始和结束的时候浪费太多的时间。
默认情况下,每一个 task 都是一个新的 JVM 实例,都需要开启和销
毁的开销。在一些情况下,JVM 开启和销毁的时间可能会比实际处理数据的时间
要消耗的长,配置 task 的 M JVM 重用可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是 1,表示一个 JVM 上最多可以
顺序执行的 task 数目(属于同一个 Job)是 1。也就是说一个 task 启一个 JVM)
如果 input 的文件非常的大,比如 1TB,可以考虑将 hdfs 上的每个 block
size 设大,比如设成 256MB 或者 512MB
3. outputformat
OutputFormat主要用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。Hadoop 自带了很多 OutputFormat 的实现,它们与InputFormat实现相对应,足够满足我们业务的需要。 OutputFormat 类的层次结构如下图所示
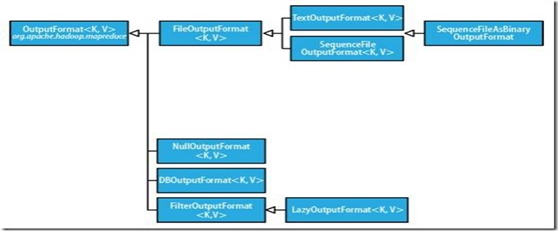
OutputFormat是MapReduce输出的基类,所有MapReduce输出都实现了 OutputFormat 接口,主要有:
TextInputFormat 、SequenceFileOutputFormat、MultipleOutputs、DBOutputFormat等
1.1.1 特殊的组件partitioner与combiner
1. partitioner定义
partitioner的作用是将mapper(如果使用了combiner的话就是combiner)输出的key/value拆分为分片(shard),每个reducer对应一个分片。默认情况下,partitioner先计算key的散列值(通常为md5值)。然后通过reducer个数执行取模运算:key.hashCode%(reducer个数)。这种方式不仅能够随机地将整个key空间平均分发给每个reducer,同时也能确保不同mapper产生的相同key能被分发到同一个reducer。也可以自定义分区去继承partition<key,value>把不同的结果写入不同的文件中
分区Partitioner主要作用在于以下两点
(1)根据业务需要,产生多个输出文件;
(2)多个reduce任务并发运行,提高整体job的运行效率
适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回5个不同int值,而reducer number设置了小于5,那就会报错。所以我们可以通过运行分析任务来确定分区数。
2. map端的combine组件
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络 IO 性能,是 MapReduce 的一种优化手段之一
combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
combiner 组件的父类就是 Reducer
combiner 和 reducer 的区别在于运行的位置:
combiner 是在每一个 maptask 所在的节点运行
reducer 是接收全局所有 Mapper 的输出结果;
combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1)自定义一个 combiner 继承 Reducer,重写 reduce 方法
2)中设置: job.setCombinerClass(CustomCombiner.class)
combiner 能够应用的前提是不能影响最终的业务逻辑,而且,combine
输出 kv 应该跟 reducer 的输入 kv 类型要对应起来
Combiner使用需要注意的是:
1.有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
2.与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
3.并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
4.一般来说,combiner和reducer它们俩进行同样的操作。