一、java基础知识回顾
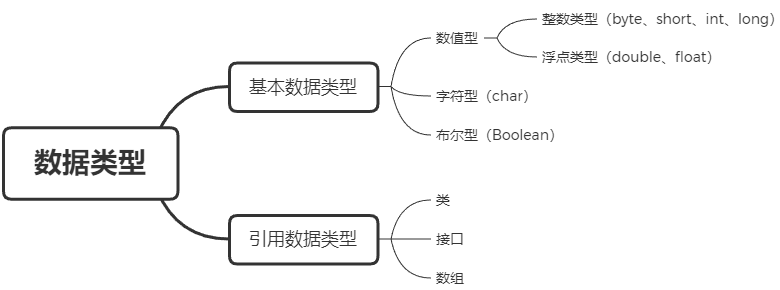
1、java中的几种基本类型,各占用多少字节?
Boolean :1字节 byte:1字节 short:2字节 int:4字节 long: 8字节 char:2字节 float:4字节 double:8字节
2、string可以被继承么,为什么?
不可以,因为string是final修饰的,而final修饰的类是不能被继承的,实现细节不允许改变,在源码中String str="a" ,和String str=new String("a")在源码里的调用是不同的:
前者调用的
public static String valueOf(int i) {
return Integer.toString(i);
}
后者调用的是
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
最后存储在final 修饰的char[]数组中
3、string ,stringbuffer,stringbuilder 的区别
String 字符串常量(final修饰,不可被继承),String是常量,当创建之后即不能更改。(可以通过StringBuffer和StringBuilder创建String对象(常用的两个字符串操作类)。)
StringBuffer 字符串变量(线程安全),其也是final类别的,不允许被继承,其中的绝大多数方法都进行了同步处理,包括常用的Append方法也做了同步处理(synchronized修饰)。其自jdk1.0起就已经出现。其toString方法会进行对象缓存,以减少元素复制开销。
StringBuilder 字符串变量(非线程安全)其自jdk1.5起开始出现。与StringBuffer一样都继承和实现了同样的接口和类,方法除了没使用synch修饰以外基本一致,不同之处在于最后toString的时候,会直接返回一个新对象。
4、ArrayList 和Linkedlist的区别
1.ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
2.相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
3.LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
5、类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当在new的时候,他们的执行顺序?
父类静态成员和静态代码块->子类静态成员和静态代码块->父类非静态成员和非静态代码块->父类构造方法->子类非静态成员和非静态代码块->子类构造方法
TestCode
//父类
public class A {
public static String a=printStr("父类的静态变量");
public String s = printStr("父类的非静态变量");
static {
printStr("父类的静态块");
}
{
printStr("父类的非静态块");
}
public A(){
printStr("父类构造方法");
}
public static String printStr(String str){
System.out.println(str);
return str;
}
}
//子类
public class B extends A {
public static String b=printStr("子类的静态变量");
public String st = printStr("子类的非静态变量");
static {
printStr("子类的静态块");
}
{
printStr("子类的非静态块");
}
public B(){
printStr("子类的构造方法");
}
//main
public static void main(String[] args) {
new B();
}
}
6、用过哪些map类,都有什么区别,hashmap是线程安全的么,并发下使用的map是什么,他们的内部实现原理分别是什么,比如存储方式,hashcode,扩容,默认容量等。
简述: hashMap是线程不安全的,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,采用哈希表来存储的。
7、有没有有顺序的map实现类,如果有,他们是怎么保证有序的?
TreeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。
8、抽象类和接口的区别,类可以继承多个类么,接口开业继承多个接口么,类可以实现多个接口么?
1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。
9、继承和聚合的区别在哪里?
继承指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识,在设计时一般没有争议性;
聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
10、讲讲你理解的nio和bio的区别是什么,谈谈reactor的模型。
IO(BIO)是面向流的,NIO是面向缓冲区的
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
11、反射的原理,反射创建类实例的三种方式
12、反射中,Class.forName 和 ClassLoader的区别。
13、描述动态代理的几种实现方式,分别说出相应的优缺点。 动态代理与 cglib 实现的区别 。
Jdk cglib jdk底层是利用反射机制,需要基于接口方式,这是由于
Proxy.newProxyInstance(target.getClass().getClassLoader(),<br> target.getClass().getInterfaces(), this);
Cglib则是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk
14、为什么CGlib可以对接口实现代理。
15、final的用途
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
16、写出三种单例模式的实现
懒汉式单例:
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
饿汉式单例:
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
静态内部类:
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
枚举:
public enum Singleton {
INSTANCE;
public void whateverMethod() {
}
}
双重校验锁:
public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
17、如何在父类为子类自动完成所有的hashcode 和equals实现?这么做有什么优劣?
同时复写hashcode和equals方法,优势可以添加自定义逻辑,且不必调用超类的实现。
18、结合oo的设计理念,谈谈访问修饰符public 、private 、 default 的应用设计中的作用?
访问符修饰,主要标识修饰块的作用域,方便隔离防护。
| 作用域 | 当前类 | 同一package | 子孙类 | 其他package |
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不仅可以跨类访问,而且允许跨包(package)访问。
private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的类、属性以及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
protect: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护形”。被其修饰的类、属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。
default:即不加任何访问修饰符,通常称为"默认访问模式"。该模式下,只允许在同一个包中进行访问。
19、深拷贝和浅拷贝的区别
20、数组和链表数据结构描述,各自的时间复杂度。
21、error 和exception的区别,CheckedException ,RuntimeException的区别。
22、请列出五个运行时异常。
23、在自己的代码中,如果创建一个 java.lang.String 对象,这个对象是否可以被类加载器加载?为什么
24、说一说你对 java.lang.Object 对象中 hashCode 和 equals 方法的理解。在什么场景下需要重新实现这两个方法。
25、在 jdk1.5 中,引入了泛型,泛型的存在是用来解决什么问题。
26、这样的 a.hashcode() 有什么用,与 a.equals(b)有什么关系。
27、有没有可能 2 个不相等的对象有相同的 hashcode。
28、Java 中的 HashSet 内部是如何工作的。
29、什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决。
30、 java 中的 Math.round(-1.5) 等于多少?
31、 java 中 IO 流分为几种?(功能和类型区分)
32、Files的常用方法有哪些?
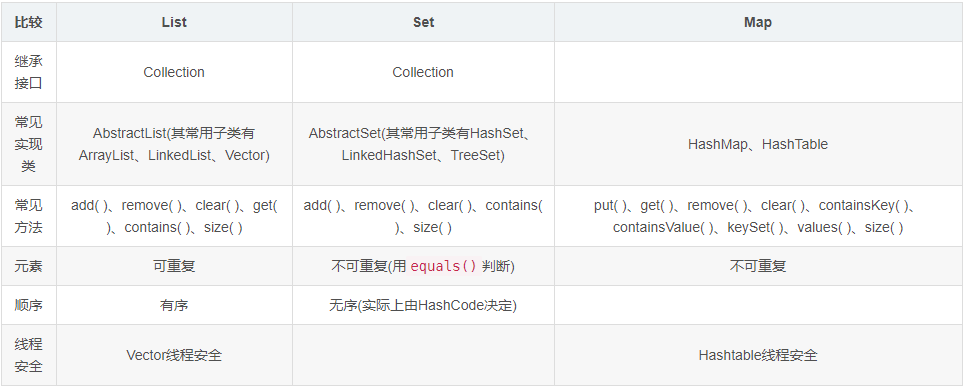
33、List、Set、Map的区别是什么?
List:
List的元素以线性方式存储,可以存放重复对象,List主要有以下两个实现类:
ArrayList : 长度可变的数组,可以对元素进行随机的访问,向ArrayList中插入与删除元素的速度慢。 JDK8 中ArrayList扩容的实现是通过grow()方法里使用语句newCapacity = oldCapacity + (oldCapacity >> 1)(即1.5倍扩容)计算容量,然后调用Arrays.copyof()方法进行对原数组进行复制。
LinkedList: 采用链表数据结构,插入和删除速度快,但访问速度慢。
Set:
Set中的对象不按特定(HashCode)的方式排序,并且没有重复对象,Set主要有以下两个实现类:
HashSet: HashSet按照哈希算法来存取集合中的对象,存取速度比较快。当HashSet中的元素个数超过数组大小*loadFactor(默认值为0.75)时,就会进行近似两倍扩容(newCapacity = (oldCapacity << 1) + 1)。
TreeSet :TreeSet实现了SortedSet接口,能够对集合中的对象进行排序。
Map:
Map是一种把键对象和值对象映射的集合,它的每一个元素都包含一个键对象和值对象。 Map主要有以下两个实现类:
HashMap:HashMap基于散列表实现,其插入和查询的开销是固定的,可以通过构造器设置容量和负载因子来调整容器的性能。
LinkedHashMap:类似于HashMap,但是迭代遍历它时,取得的顺序是其插入次序,或者是最近最少使用(LRU)的次序。
TreeMap:TreeMap基于红黑树实现。查看时,它们会被排序。TreeMap是唯一的带有subMap()方法的Map,subMap()可以返回一个子树。
34、