Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
在很典型的功能业务场景中使用kakfa 消费上游处理结果消息,当做一个消费中间件,处理完毕后sink 到下一流程
在使用的途中,我们需要了解kafka 对应的消息处理策略以及为了避免消息堆积,多线程消费如何进行处理,以及一致性保证问题。
在策略上本次处理考虑使用批量消息拉取,在配置文件中进行设置,在factory中进行设置并行数。
首先设置分区数为3(可使用 cli 工具,或者kafka admin 客户端api调用创建分区):

注意并行数最好和topic 分区数一一对应,如果partition 数量多于并发数,每个consumer 轮询分区来进行消费,如果并发数多于partition,则会造成资源浪费,多出来的consumer会处于闲置状态。
ack提交策略设置为 MANUAL_IMMEDIATE ,处理逻辑为处理完之后再进行ack 手动提交,如果使用RECORD方式,在程序挂掉的时候可能会造成消息丢失。

消费使用上期的kafka的策略模式。
在handle中,由于使用的分批次拉取消息,遍历records,在每条record进行处理的时候,在线程池中手动创建一个线程,处理对应消息,当消息处理完毕后,手动ack提交offset。

实际处理流程为,3并行度来进行每个分区的消息拉取
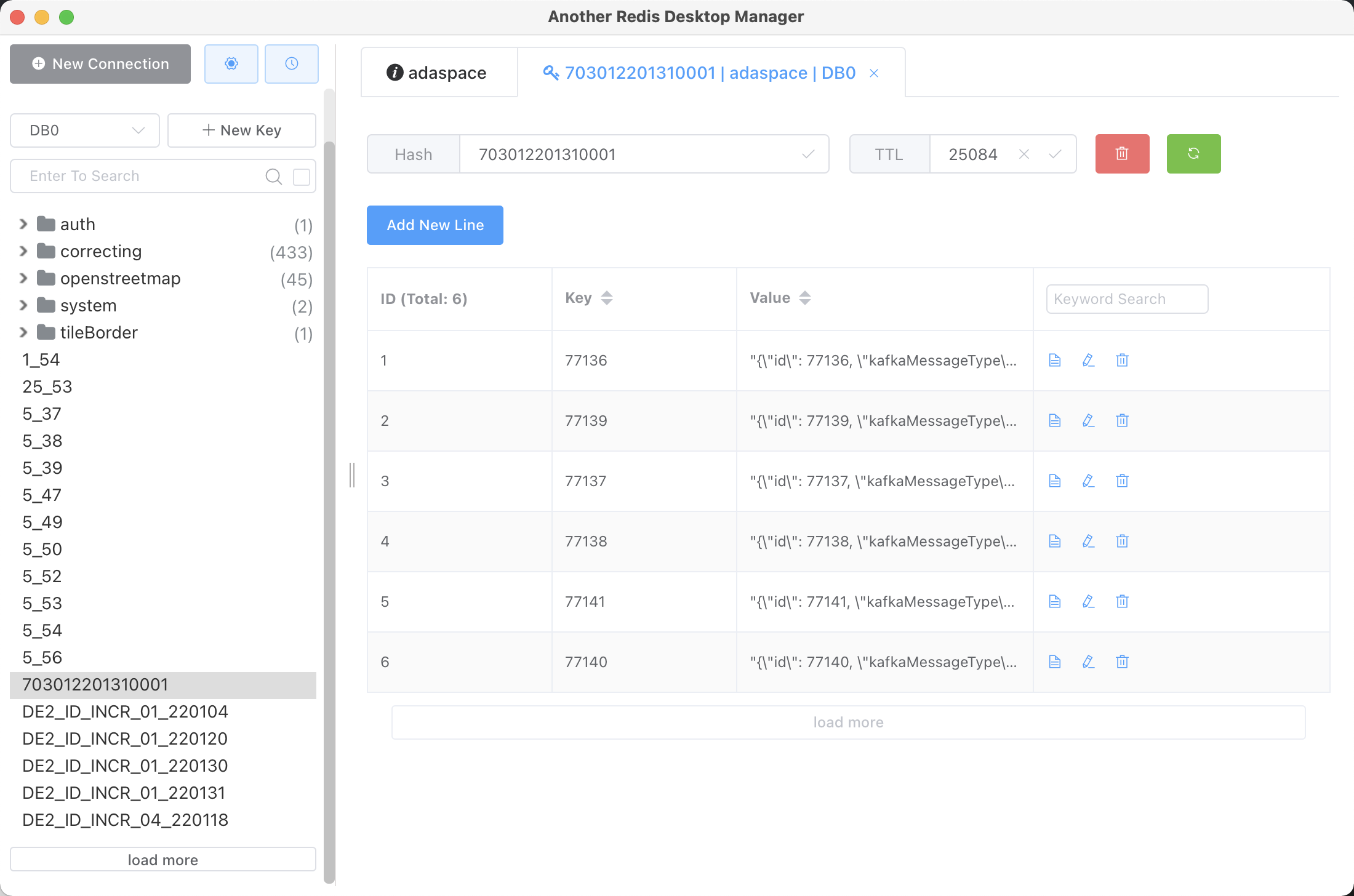
在处理的时候使用保证进度的顺序性,采用redis 来进行消息缓存,且避免数据库的频繁读写,当处理完成,统一写入postgre